Send HTTP Requests As Fast As Possible in Python
It is easy to send a single HTTP request by using the requests package. What if I want to send hundreds or even millions of HTTP requests asynchronously? This article is an exploring note to find fastest way to send HTTP requests in python.
1. Synchronous
The most simple, easy-to-understand way, but also the slowest way. I forge 100 links for the test by this magic python list operator:
url_list = ["https://www.google.com/", "https://www.bing.com"] * 50
Code:
import requests
import time
def download_link(url:str) -> None:
result = requests.get(url).content
print(f'Read {len(result)} from {url}')
def download_all(urls:list) -> None:
for url in urls:
download_link(url)
url_list = ["https://www.google.com/", "https://www.bing.com"] * 50
start = time.time()
download_all(url_list)
end = time.time()
print(f'download {len(url_list)} links in {end - start} seconds')
Error:
Traceback (most recent call last):
File "/Users/shyambabu/Desktop/Code/async/http.py", line 1, in <module>
import requests
ModuleNotFoundError: No module named 'requests'
If you are getting above error while running the script. Then first you need to install requests library:
pip install requests
It takes about 52 seconds to finish downloading 100 links.
Output:
Read 16327 from https://www.google.com/
Read 73910 from https://www.bing.com
Read 16258 from https://www.google.com/
Read 74165 from https://www.bing.com
Read 16314 from https://www.google.com/
Read 74175 from https://www.bing.com
...
...
download 100 links in 52.747859954833984 seconds
As a synchronous solution, there are still rooms to improve the time complexity. We can leverage the Session object to further increase the speed. The Session object will use urllib3’s connection pooling, which means, for repeating requests to the same host, the Session object’s underlying TCP connection will be re-used, hence gain a performance increase.
So if you’re making several requests to the same host, the underlying TCP connection will be reused, which can result in a significant performance increase — Session Objects
To ensure the request object exit no matter success or not, I am going to use the with statement as a wrapper. the with keyword in Python is just a clean solution to replace try… finally….
Now, Let’s see how many seconds are saved by changing to this:
Code:
import requests
from requests.sessions import Session
import time
url_list = ["https://www.google.com/", "https://www.bing.com"] * 50
def download_link(url:str,session:Session) -> None:
with session.get(url) as response:
result = response.content
print(f'Read {len(result)} from {url}')
def download_all(urls:list) -> None:
with requests.Session() as session:
for url in urls:
download_link(url,session=session)
start = time.time()
download_all(url_list)
end = time.time()
print(f'download {len(url_list)} links in {end - start} seconds')
Looks like the performance is really boosted to 42.x seconds.
Output:
Read 74112 from https://www.bing.com
Read 16277 from https://www.google.com/
Read 74112 from https://www.bing.com
Read 16277 from https://www.google.com/
Read 74112 from https://www.bing.com
...
...
download 100 links in 42.30887722969055 seconds
But this is still too slow, let’s try to using the multi-threading solution.
2. Multi-Threading
Here, we are going to use queue to hold 100 links and create 10 HTTP download worker threads to consume the 100 links asynchronously.
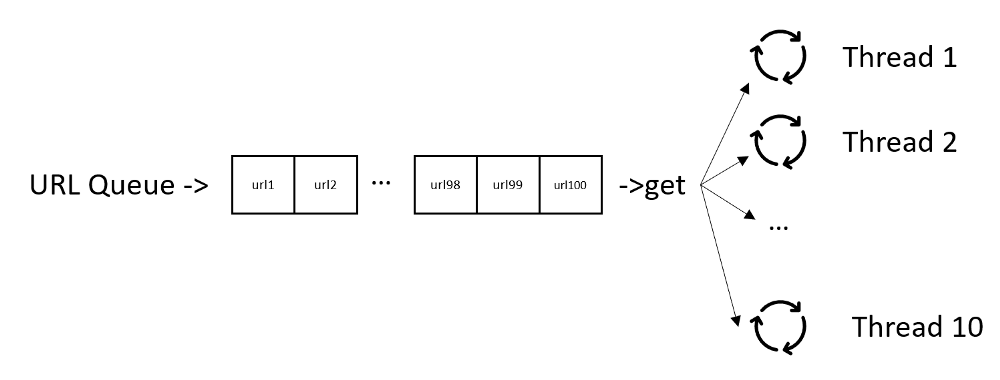
To use the Session object, it is a waste to create 10 Session objects for 10 threads, I want one Session object and reuse it for all downloading work. To make it happen, The code will leverage the local object from threading package, so that 10 thread workers will share one Session object.
Sample:
from threading import Thread,local
...
thread_local = local()
Code:
import time
import requests
from requests.sessions import Session
from threading import Thread,local
from queue import Queue
url_list = ["https://www.google.com/", "https://www.bing.com"] * 50
q = Queue(maxsize=0) #Use a queue to store all URLs
for url in url_list:
q.put(url)
thread_local = local() #The thread_local will hold a Session object
def get_session() -> Session:
if not hasattr(thread_local,'session'):
thread_local.session = requests.Session() # Create a new Session if not exists
return thread_local.session
def download_link() -> None:
'''download link worker, get URL from queue until no url left in the queue'''
session = get_session()
while True:
url = q.get()
with session.get(url) as response:
print(f'Read {len(response.content)} from {url}')
q.task_done() # tell the queue, this url downloading work is done
def download_all(urls) -> None:
'''Start 10 threads, each thread as a wrapper of downloader'''
thread_num = 10
for i in range(thread_num):
t_worker = Thread(target=download_link)
t_worker.start()
q.join() # main thread wait until all url finished downloading
print("start work")
start = time.time()
download_all(url_list)
end = time.time()
print(f'download {len(url_list)} links in {end - start} seconds')
Output:
Read 74106 from https://www.bing.com
Read 74086 from https://www.bing.com
Read 16339 from https://www.google.com/
Read 16284 from https://www.google.com/
Read 16295 from https://www.google.com/
Read 74106 from https://www.bing.com
Read 73842 from https://www.bing.com
...
...
download 100 links in 6.94016695022583 seconds
This is the fast! way, faster than the synchronous solution.
3. Multi-Threading by ThreadPoolExecutor
Python also provides ThreadPoolExecutor to perform multi-thread work
ThreadPoolExecutor is a form of multithreading, with a simpler API to use than directly using Threads, where you submit tasks indeed. However, tasks can submit other tasks, so they need not be independent.
In the Thread and Queue version, there is a while True loop in the HTTP request worker, this makes the worker function tangled with Queue and needs additional code change from the synchronous version to the asynchronous version.
Using ThreadPoolExecutor, and its map function, we can create a Multi-Thread version with very concise code, require minimum code change from the synchronous version.
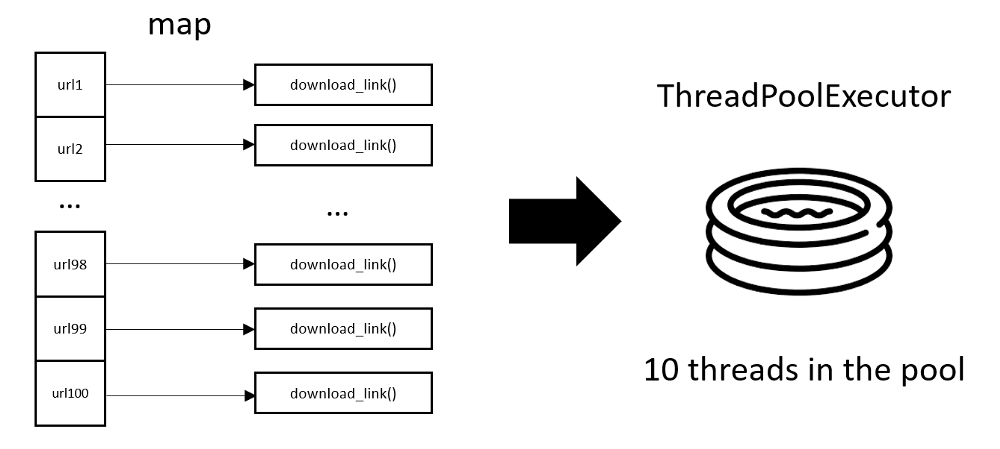
Code:
import requests
from requests.sessions import Session
import time
from concurrent.futures import ThreadPoolExecutor
from threading import Thread,local
url_list = ["https://www.google.com/","https://www.bing.com"]*50
thread_local = local()
def get_session() -> Session:
if not hasattr(thread_local,'session'):
thread_local.session = requests.Session()
return thread_local.session
def download_link(url:str):
session = get_session()
with session.get(url) as response:
print(f'Read {len(response.content)} from {url}')
def download_all(urls:list) -> None:
with ThreadPoolExecutor(max_workers=10) as executor:
executor.map(download_link,url_list)
start = time.time()
download_all(url_list)
end = time.time()
print(f'download {len(url_list)} links in {end - start} seconds')
And the output is as fast as the Thread-Queue version:
Read 16283 from https://www.google.com/
Read 74101 from https://www.bing.com
Read 16222 from https://www.google.com/
Read 74076 from https://www.bing.com
Read 16247 from https://www.google.com/
Read 73841 from https://www.bing.com
...
...
download 100 links in 5.662416219711304 seconds
4. asyncio with aiohttp
asyncio is the future, and it is fast. Some folks use it making 1 million HTTP requests with Python asyncio and aiohttp. Although asyncio is super fast, it uses zero Python Multi-Threading.
Believe it or not, asyncio runs in one thread, in one CPU core.
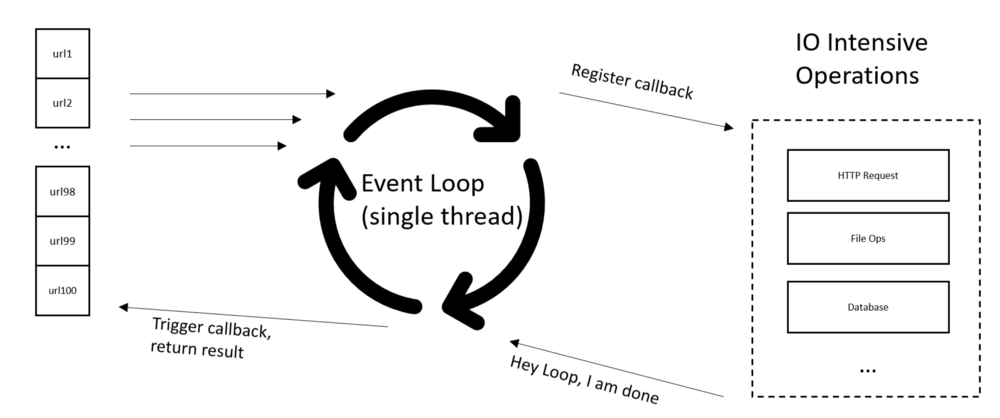
The event loop implemented in asyncio is almost the same thing that is beloved in Javascript.
Asyncio is so fast that it can send almost any number of requests to the server, the only limitation is your machine and internet bandwidth.
Too many HTTP requests send will behave like “attacking”. Some web site may ban your IP address if too many requests are detected, even Google will ban you too. To avoid being banned, I use a custom TCP connector object that specified the max TCP connection to 10 only. (it may safe to change it to 20)
my_conn = aiohttp.TCPConnector(limit=10)
Code:
import asyncio
import time
import aiohttp
from aiohttp.client import ClientSession
async def download_link(url:str,session:ClientSession):
async with session.get(url) as response:
result = await response.text()
print(f'Read {len(result)} from {url}')
async def download_all(urls:list):
my_conn = aiohttp.TCPConnector(limit=10)
async with aiohttp.ClientSession(connector=my_conn) as session:
tasks = []
for url in urls:
task = asyncio.ensure_future(download_link(url=url,session=session))
tasks.append(task)
await asyncio.gather(*tasks,return_exceptions=True) # the await must be nest inside of the session
url_list = ["https://www.google.com", "https://www.bing.com"] * 50
print(url_list)
start = time.time()
asyncio.run(download_all(url_list))
end = time.time()
print(f'download {len(url_list)} links in {end - start} seconds')
Error:
Traceback (most recent call last):
File "/Users/shyambabu/Desktop/Code/async/http_asycio.py", line 3, in <module>
import aiohttp
ModuleNotFoundError: No module named 'aiohttp'
If you got above error, while executing the script, then first need to install aihttp module.
Command:
pip install aiohttp
Output:
Read 16313 from https://www.google.com
Read 16273 from https://www.google.com
Read 73941 from https://www.bing.com
Read 16240 from https://www.google.com
Read 16274 from https://www.google.com
Read 73976 from https://www.bing.com
Read 16283 from https://www.google.com
...
...
download 100 links in 4.692856788635254 seconds
And the above code finished 100 links downloading in 4.69 seconds!
Note that if you are running code in Jupyter Notebook or IPython, then you need to install one additional package.
pip install nest-asyncio
and add the following two lines of code at the beginning of the code.
import nest_asyncio
nest_asyncio.apply()