Export & Load Job with MongoDB — BigQuery
Google BigQuery
What is Google BigQuery?
— BigQuery is Google’s fully managed, petabyte scale, low cost analytics data warehouse.
Why we use Google BigQuery?
— BigQuery is NoOps — there is no infrastructure to manage and you don’t need a database administrator — so you can focus on analyzing data to find meaningful insights, use familiar SQL, and take advantage of our pay-as-you-go model.
How to use Google BigQuery?
— Signup to Google Cloud platform — GCP using your google account, start loading your data and leverage the power of this NoOps system.
Terminology used in BigQuery
Dataset
A dataset is contained within a specific project. Datasets enable you to organize and control access to your tables. A table must belong to a dataset, so you need to create at least one dataset before loading data into BigQuery.
Tables
A BigQuery table contains individual records organized in rows, and a data type assigned to each column (also called a field).
Schema
Each Every table is defined by a schema that describes field names, types, and other information. You can specify the schema of a table during the initial table creation request, or you can create a table without a schema and declare the schema in the query or load job that first populates the table. If you need to change the schema later, you can update the schema.
Loading Data into BigQuery
we are going to use a mongoDB server to export our data and going to import into BigQuery.
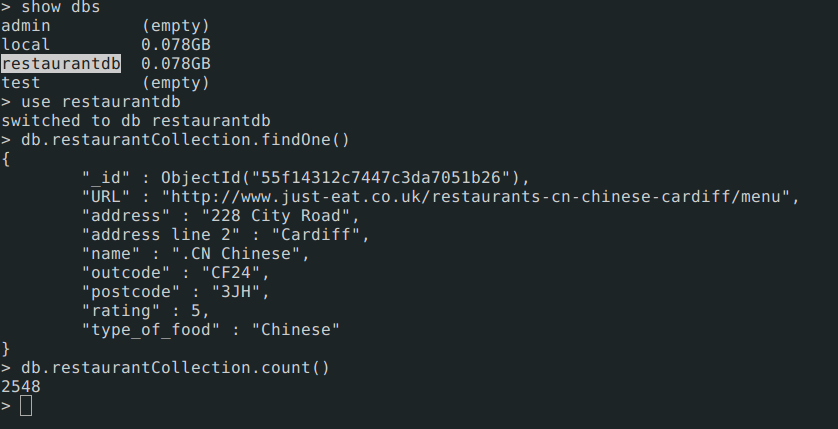
Step 1: Export data from MongoDB
We have a database in mongoDB server with name restaurantdb with collection name restaurantCollection. We are going to export using mongoexportbinary available with mongodb server tools.
mongoexport -d restaurantdb -c restaurantCollection -o restaurant.json
Once export is done, we can see content of restaurant.json file.
head -n 1 restaurant.json
{
"name": ".CN Chinese",
"URL": "http://www.just-eat.co.uk/restaurants-cn-chinese-cardiff/menu",
"outcode": "CF24",
"postcode": "3JH",
"address": "228 City Road",
"_id": {
"$oid": "55f14312c7447c3da7051b26"
},
"type_of_food": "Chinese"
}
Step 2: Prepare schema for Table
Now we have our data ready in json format to be imported into BQ table. We need to design schema in order to import these records. Schema is skeleton of each field with datatype and the field not described in schema will not be imported. We have given all fields as NULLABLE ie, if field didn’t came in any records BQ will define null value.
cat restaurantSchema.json
[
{
"name": "name",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "URL",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "address",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "outcode",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "postcode",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "type_of_food",
"type": "STRING",
"mode": "NULLABLE"
}
]
Step 3: Google Cloud SDK Installation
Follow the link to do the installation : https://cloud.google.com/sdk/
Once installation is done, run following command to verify account setup.
gcloud auth list
gcloud config list
Step 4: Create BigQuery Dataset
Option 1: Create dataset through
bqcommand line interface
bq mk -d --data_location=US BQ_Dataset
Tp verify your dataset creation
bq ls
datasetId
----------------
BQ_Dataset
Option 2: Create dataset through BigQuery Google Console
Go to your BigQuery in google console. https://bigquery.cloud.google.com
- Click on
careticon, thenCreate new dataset.
- Enter the dataset name
- Enter the location region
- Enter the expiry date
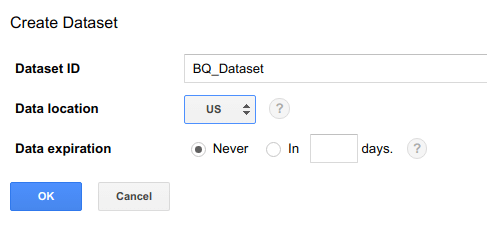
Learn more about create dataset
Step 5: Load data into BigQuery
Now we have two json file. One for the data and other for the schema.
tree
.
├── restaurant.json
└── restaurantSchema.json
0 directories, 2 files
Run command to load data into BQ. Once you submit load job, it will take seconds to minute depends on size of data you are importing into BQ table.
bq load --project_id=mimetic-slate-179915 \
--source_format=NEWLINE_DELIMITED_JSON --max_bad_records 10 \
BQ_Dataset.Restaurant ./restaurant.json /restaurantSchema.json
--max_bad_records 10are additional flags to allow 10 bad records while importing your job, exceeding this value will result in import failure.
Import through Cloud Storage

Another methods to import the data through Cloud Storage, this method is lot faster compared to above one.
Read more about creating buckets
// To create Cloud storage bucket for this example.
gsutil mb gs://bq-storage
// To verify bucket creation
gsutil ls
gs://bq-storage/
Now , we will upload our data restaurant.json to storage in bucket gs://bq-storage/
gsutil cp restaurant.json gs://bq-storage/restaurant.json
Now, we can use storage path of object to import into BQ tables.
bq load --project_id=mimetic-slate-179915 \
--source_format=NEWLINE_DELIMITED_JSON --max_bad_records 10 \
BQ_Dataset.Restaurant \
gs://bq-storage/restaurant.json ./restaurantSchema.json
After bq load finished, run following command to verify the table creation.
bq show BQ_Dataset.Restaurant
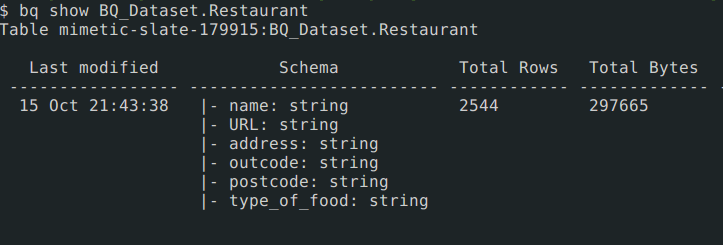
You can also verify in bigQuery UI after hitting refresh. Visit to table and click preview button. You will start seeing records in table.
More about bq CLI : https://cloud.google.com/bigquery/bq-command-line-tool
More about gsutil CLI : https://cloud.google.com/storage/docs/quickstart-gsutil
SQL Query in BQ Table
SELECT
name,
address
FROM
[mimetic-slate-179915:BQ_Dataset.Restaurant]
WHERE
type_of_food = 'Thai'
GROUP BY
name, address